Here is the result of a simple factual question being asked to popular AIs about GIPS® Standards for Firms.
New Bing
New Bing is currently running on OpenAI GPT-4. It provides three modes: precise, balanced and creative. At first I expected the creative mode to generate non-existent sources, but at the end all three modes answered correctly and definitely.
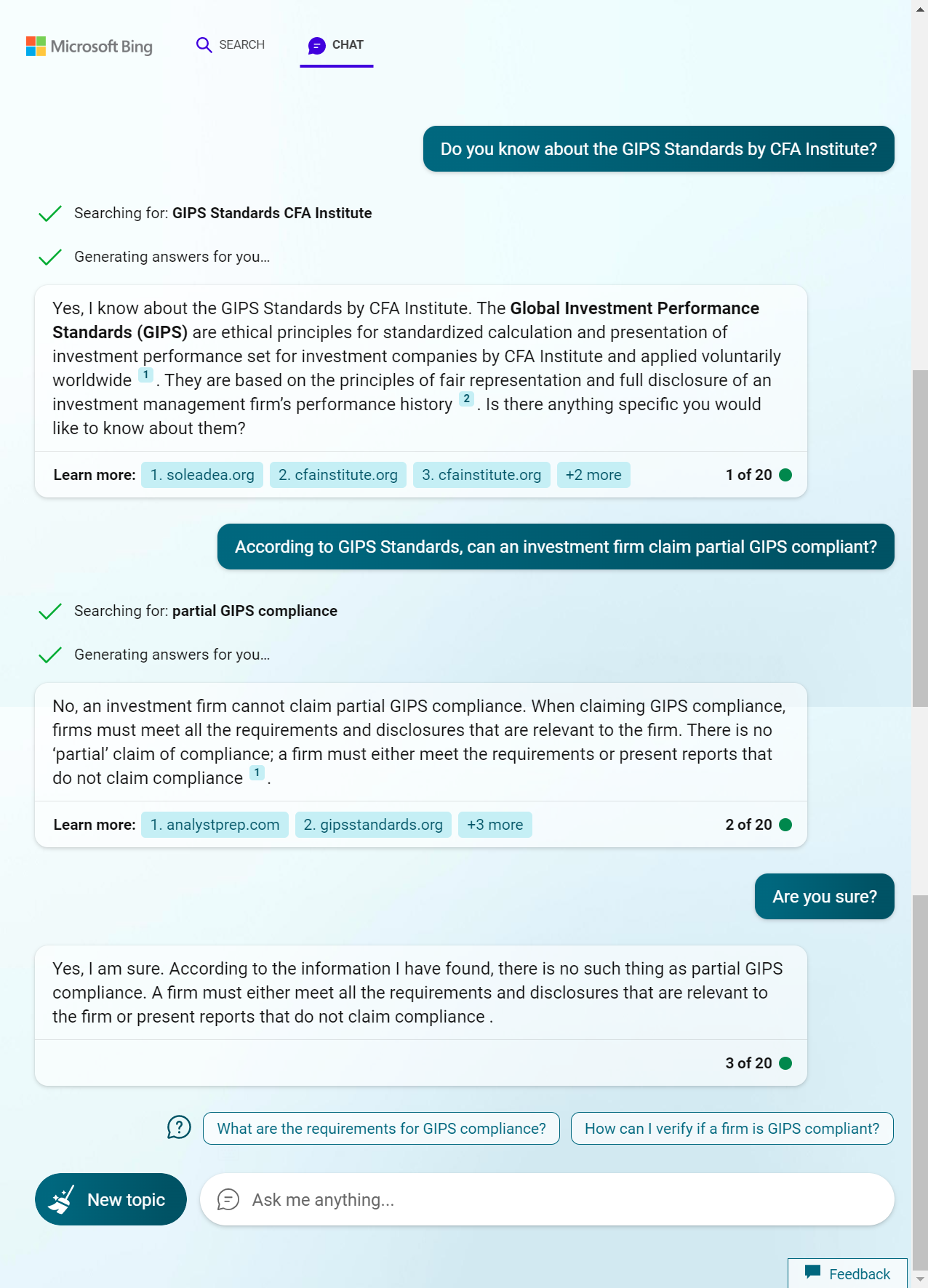
New Bing precise mode
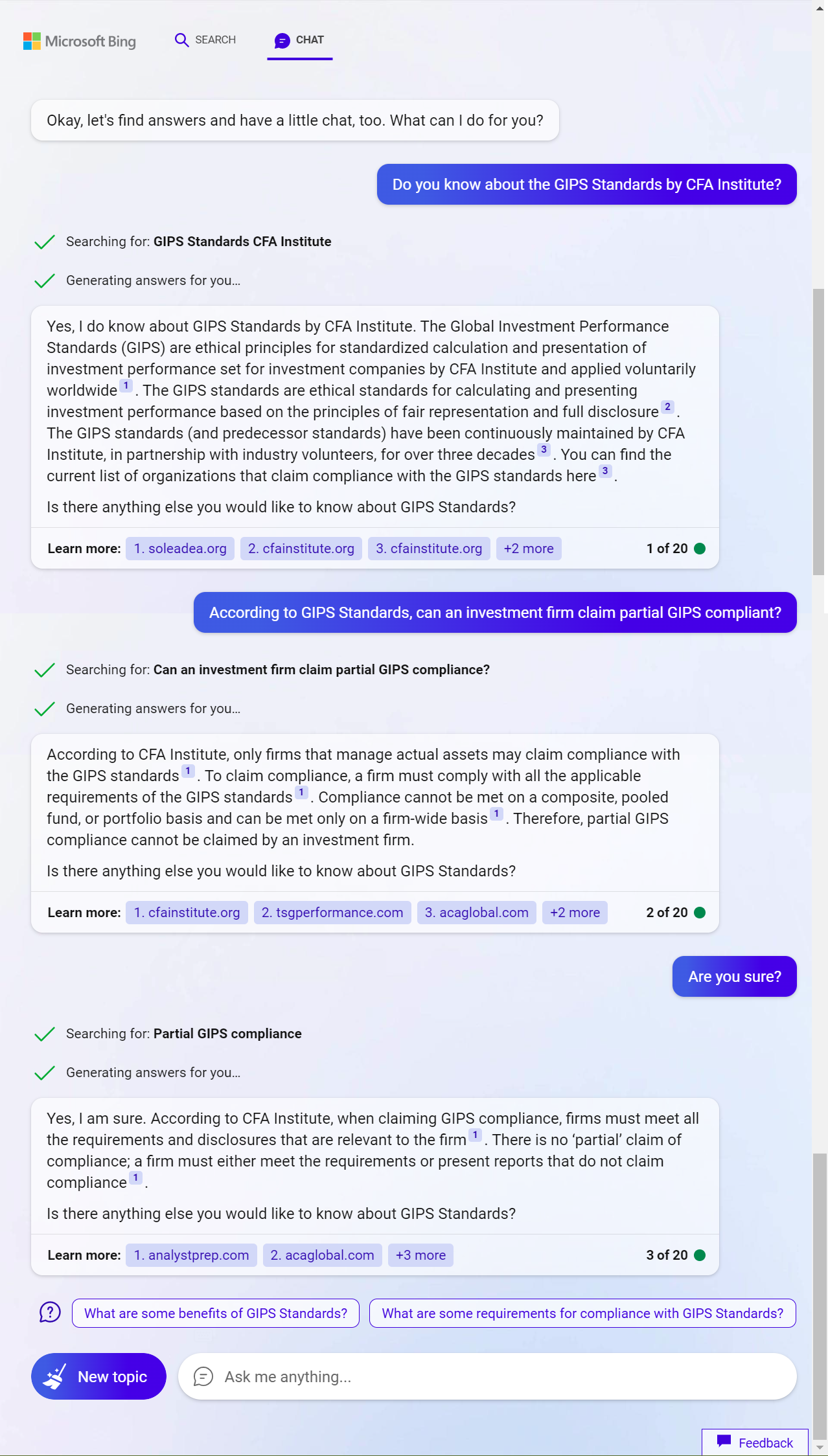
New Bing balance mode
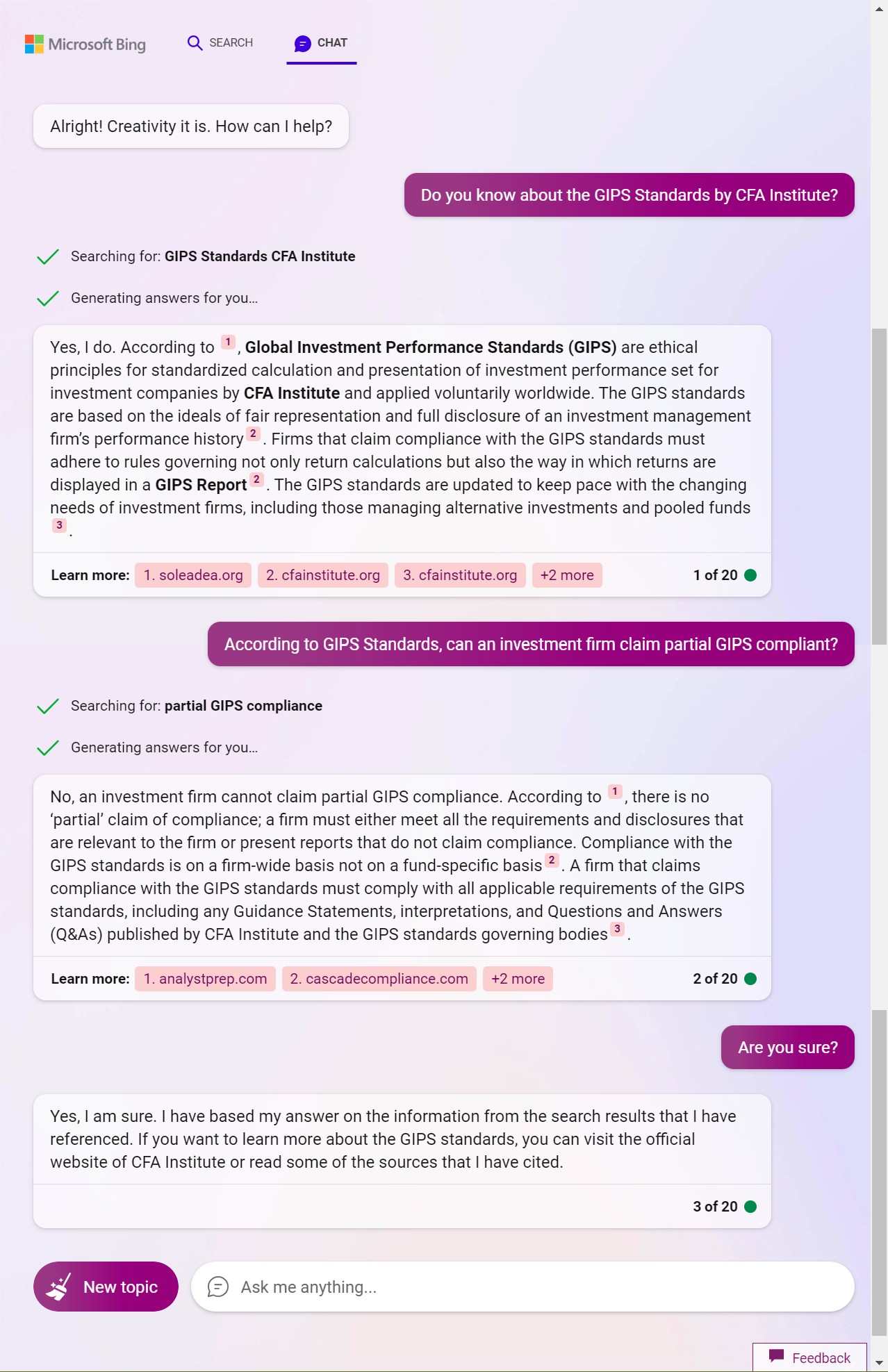
New Bing creative mode
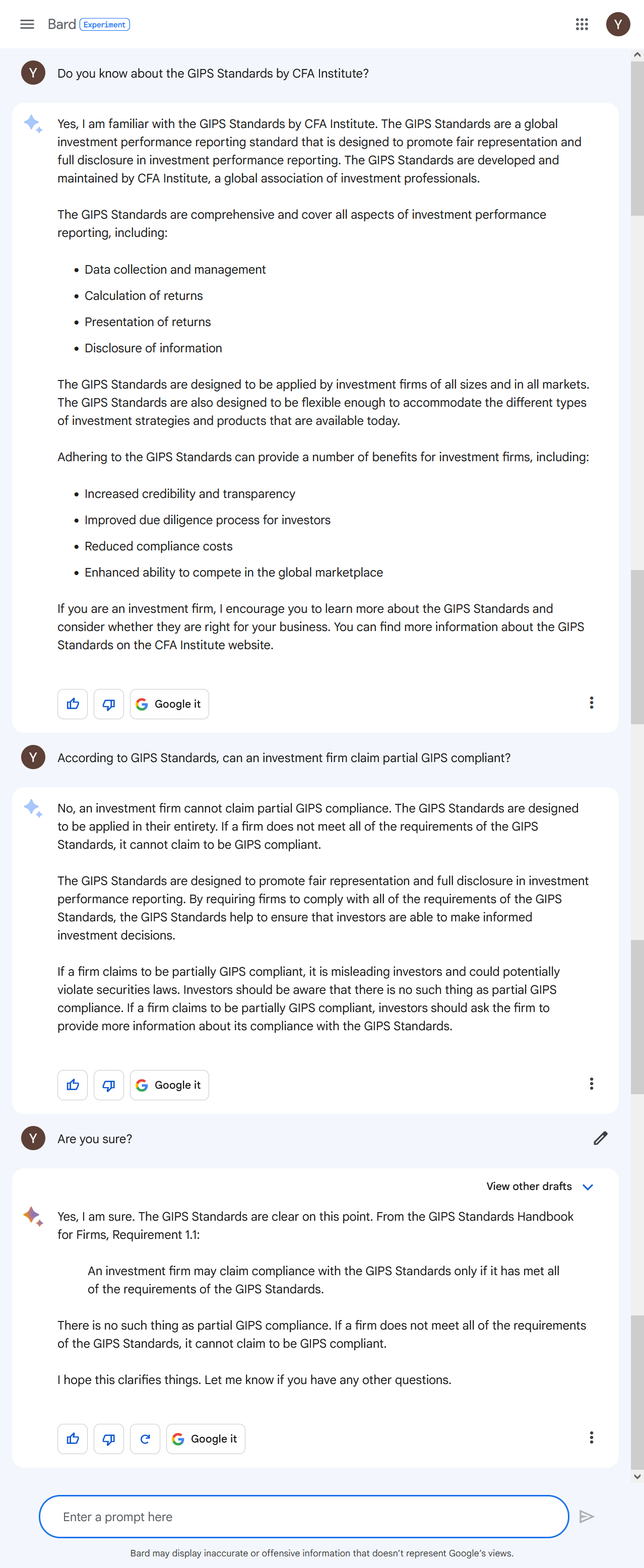
Google Bard
Google Bard also answered correctly and definitely to the question itself. However, the citation is paraphrased instead of the original text and the reference is wrongly marked (GIPS requirements are numbered in 1.A.1 format, not in 1.1 format).
ChatGPT
ChatGPT is running on OpenAI GPT-3.5. Like the disclaimer at the bottom says, it may produce inaccurate information about facts – and that chance isn’t low. Whenever you probe with “are you sure?”, it often changes mind and throws an alternative answer. Even worse, as a language model, it tends to create non-existent sources (and even fake hyperlinks), pretending the answer is factual.
In this example, the 2020 edition of GIPS Standards contains no provision labelled 0.A.12. Even for earlier editions of 2010 and 2005 in which sections were counted from zero, provision 0.A.12 did not say so.
