以下是用关于 GIPS® Standards for Firms 的一个简单事实问题来测试几个语言类AI的结果。
New Bing
New Bing 目前跑在 OpenAI GPT-4 上,提供三种模式:精准、平衡和创意。我以为创意模式可能会生成不存在的来源,不过最终三种模式都十分肯定地给出了正确答案。
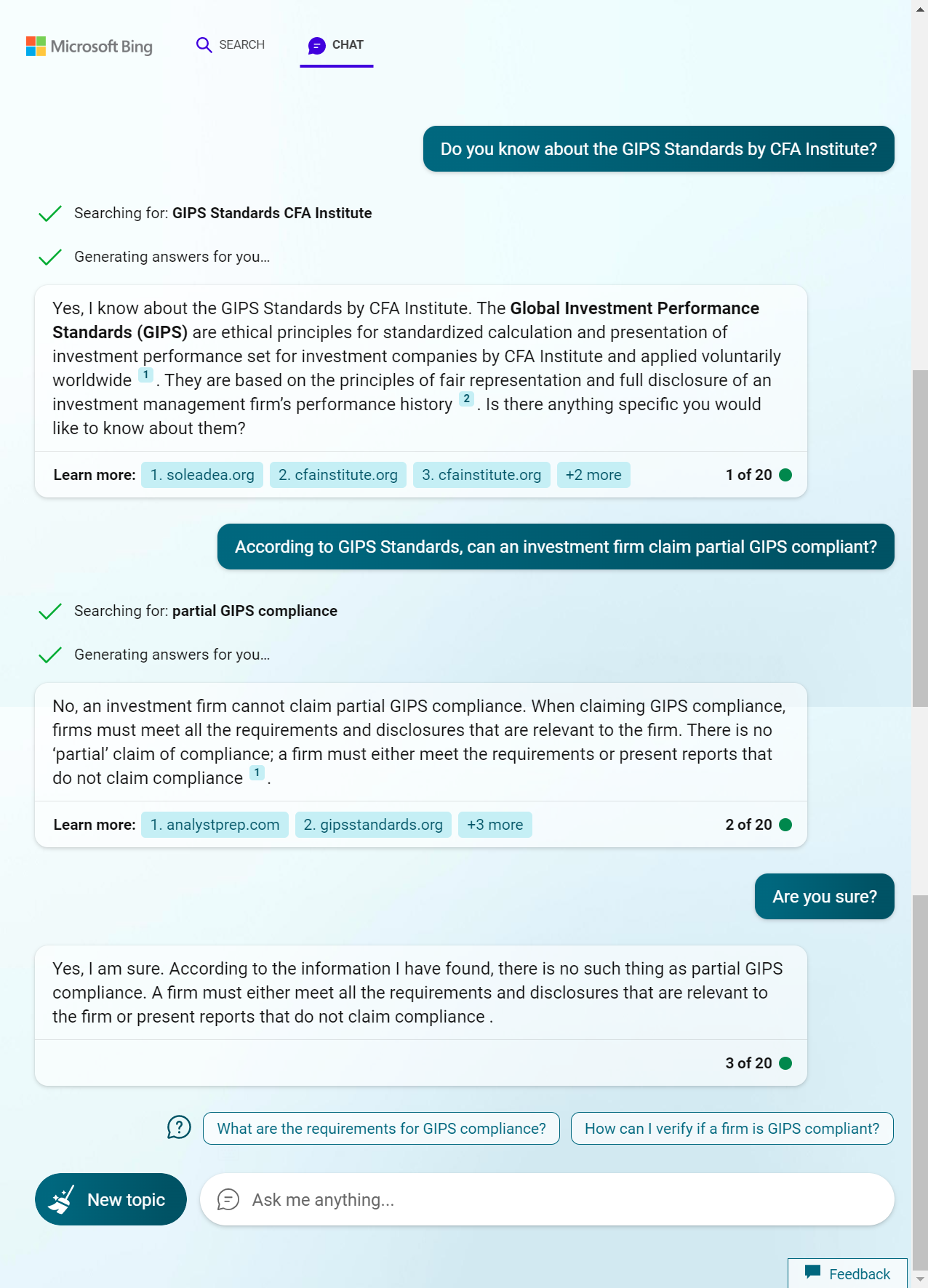
New Bing 精准模式
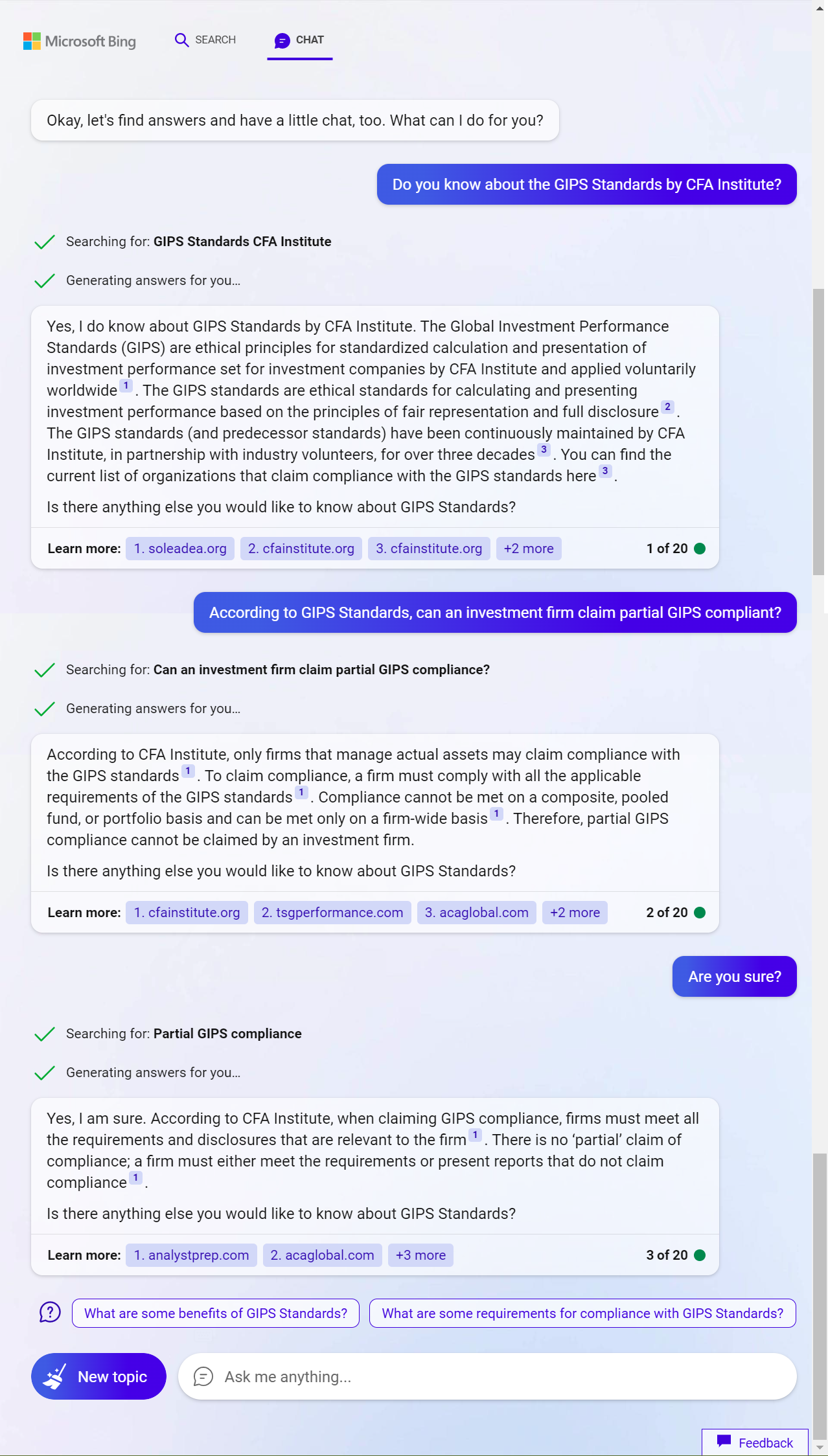
New Bing 平衡模式
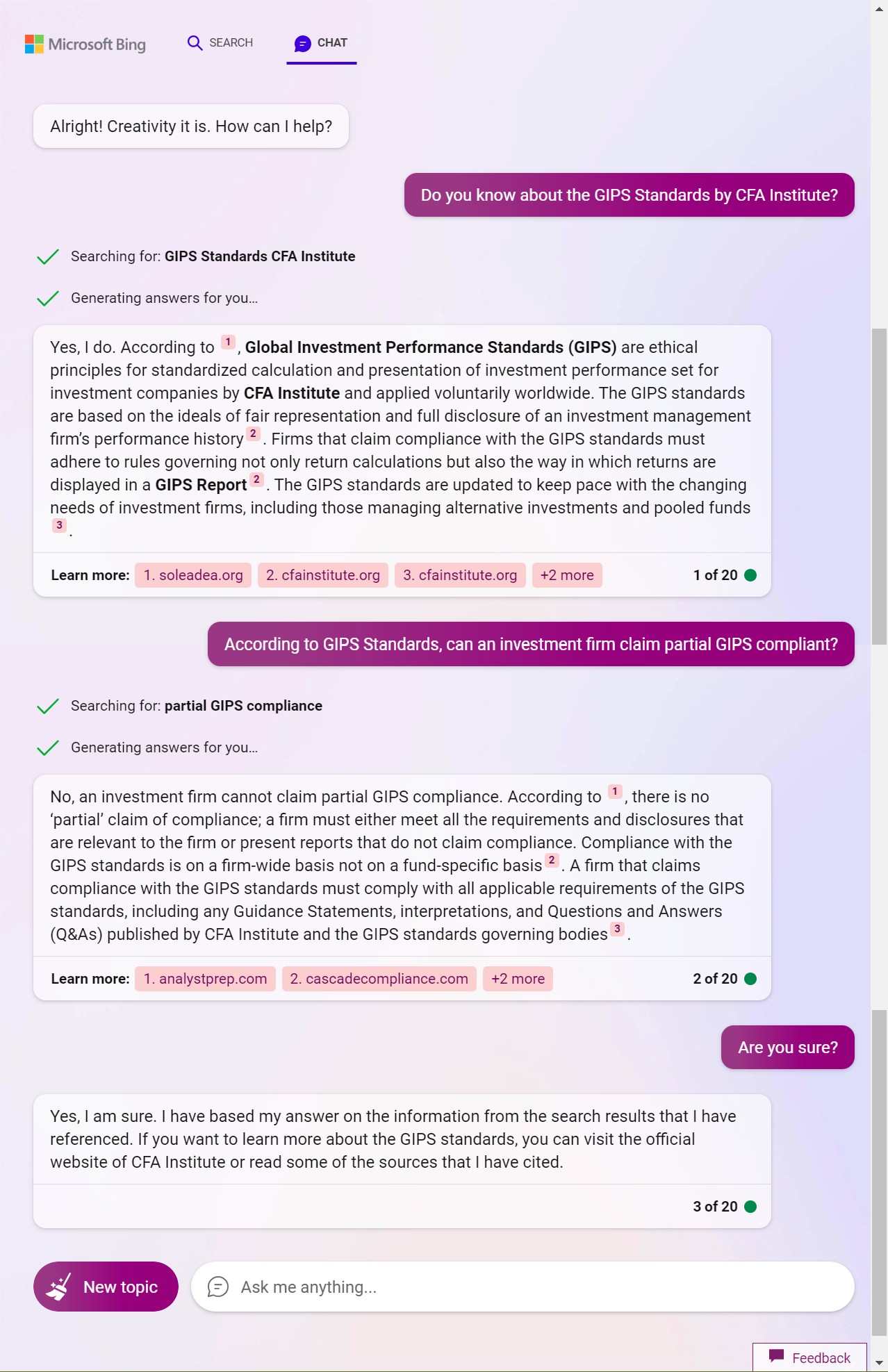
New Bing 创意模式
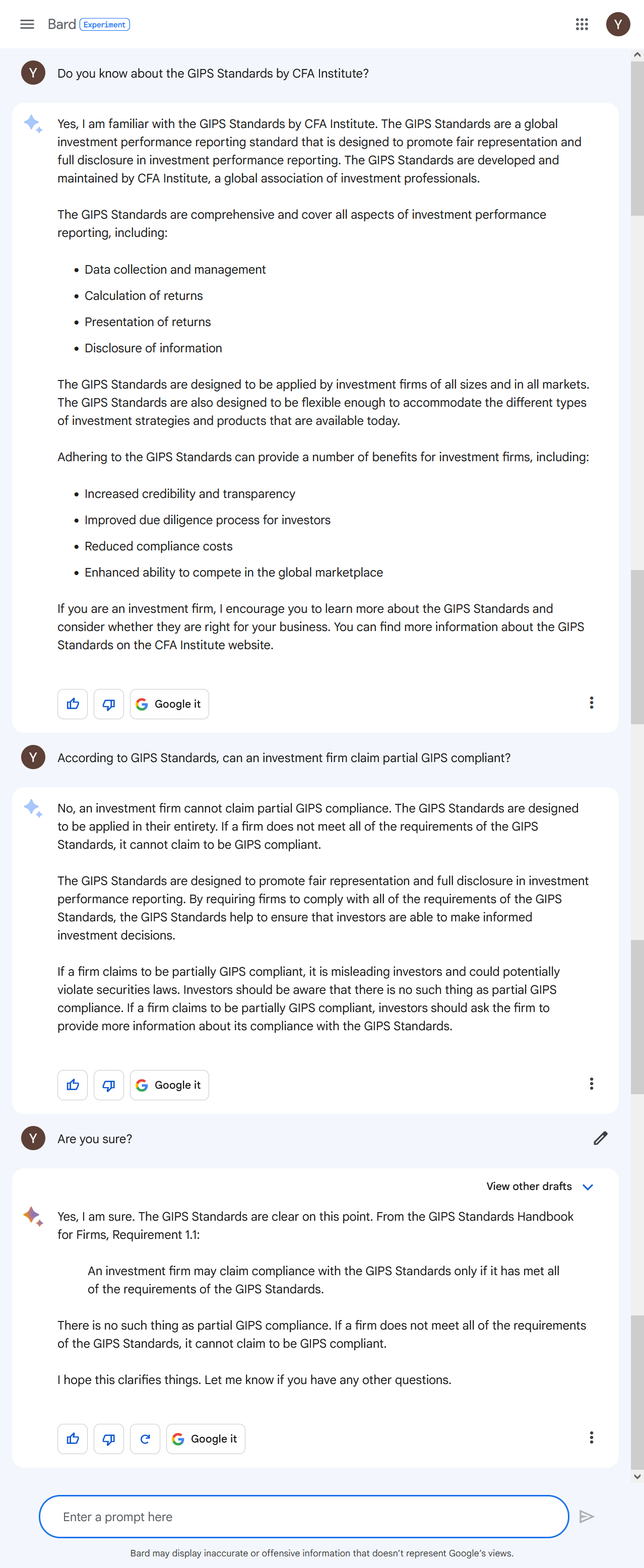
Google Bard
Google Bard 同样肯定地正确回答了问题本身,然而仔细看的话会发现引述段落并不是原文,而是重新组织过了语言,引用来源的标注也是错的(GIPS的段落编号格式是 1.A.1 ,而不是 1.1)。
ChatGPT
ChatGPT 跑在 OpenAI GPT-3.5 上,底部的免责声明说它可能会生成不准确的事实,实际上确实如此。只要一追问“你确定吗?”,ChatGPT 经常会立刻改变观点,尝试另一种答案。更大的问题是它时不时编造不存在的来源(甚至假的链接)来让回答看起来有模有样,当然这主要是因为它仅仅是一个语言模型。
比如这个例子里,2020版 GIPS 并没有标号 0.A.12 的条款。即使在从零开始标号的旧版本(比如2010或2005版)里,标号为 0.A.12 的条款内容也并非如此。
